首先,我們需要明確問題以及這個問題是否適合使用AI來解決。我們還需要確定應該使用哪一種類型的AI來處理問題,如監督式學習、非監督式學習或強化學習。
根據問題,我們會蒐集過往的資料。這些資料可能包含已知的資訊或未知的資訊。如果資料已知,可以使用監督式學習;如果資料未知,則可能只能使用非監督式學習。資料量取決於問題的複雜度。例如,預測性別相對簡單,但如果要預測身高、年齡和體重等,則需要更多的資料。
我們需要將現實問題轉化為數學問題。在監督式學習中,我們會提供一些數對(x, y),機器學習就是在找出正確的函數f(x)。機器處理的是數學式,而非現實層面問題。
學習完成後,我們將使用模型來預測結果。我們會提供一些機器學習過程中從未見過的x,機器會根據其f(x)給出一個y。利用這個y,我們可以判斷模型的好壞。
如果模型效果良好,我們將利用它來做出決策。然而,這部分與AI關係不大,因此不會詳述。
回歸問題旨在找出資料中的規律,並利用現有特徵預測另一變量,輸出的值通常具有實質意義。
舉例: 我們希望機器預測房價,給出坪數作為x,價格作為y,然後機器會利用這些資料預測出一條直線,這條直線就是f(x)。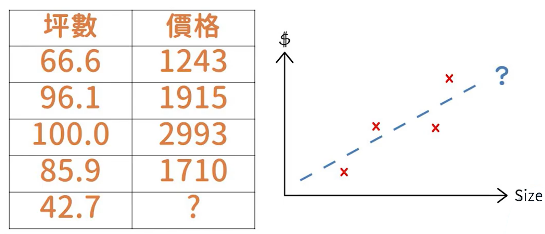
分類問題將輸入的樣本區分為事先定義好的類別,輸出的y是類別的代表號,不具有特定物理意義。
舉例: 在圖片中找出是人、桌子還是椅子,將人定義為1,桌子定義為2,椅子定義為3。若輸出為2,即表示是桌子。
分群問題將樣本依據其特性進行關聯,每組相關聯的樣本用代表點表示,可以挖掘資料的潛在特性。
常見應用: 推薦系統,當你在網頁中尋找商品時,其他相關商品會跳出來,這通常使用了分群技術。
異常分析: 在資料中找出與其他樣本不同的異常樣本,例如,駭客攻擊會導致網頁異常,可利用非監督式學習的分群法來檢測異常。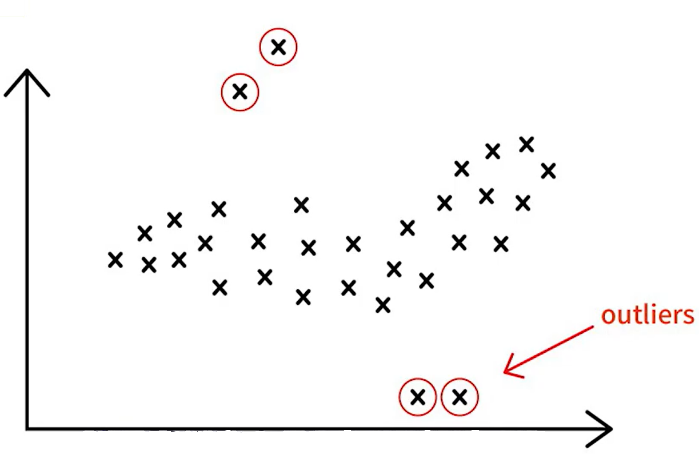
電腦遊戲中的AI設計多屬於演算法設計,非機器學習。但隨著強化學習的興起,越來越多遊戲使用強化學習技術設計AI。例如,IBM的深藍電腦下西洋棋打敗世界棋王、Google DeepMind的AlphaGo打敗韓國世界棋王。

